Let us start of by defining what alphanumeric code is. Alphanumeric codes are binary codes that denote or represent data that is alphanumeric in nature. Examples of alphanumeric data are letters and punctuation marks, just to mention a few. In order to understand this you must bear in mind that computers only understand binary numbers i.e. ones (1) and zeros (0). The importance of alphanumeric codes comes to the fore when you realize that a computer must interact with several hardware components i.e. input or output devices.
Table of Contents
Different Types Of Alphanumeric Code
ASCII – American Standard Code For Information Interchange
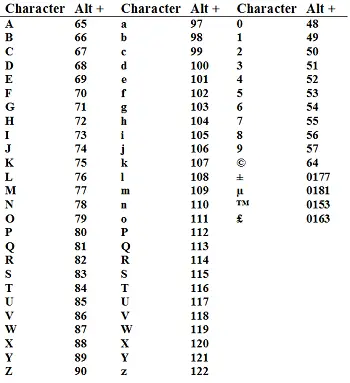
This is one of what is commonly used for computers nowadays. This is what is used to denote alphanumeric data on some modern day computers. This is based on a 7 bit code system. It is premised on the arrangement of the common English alphabets in use today. This should make you realize something; ASCII Code is not well suited for handling other languages other than English.
ASCII came onto the scene around 1967 after having been derived from telegraph-based codes. Let us look at the breakdown of the alphanumeric data representable under the ASCII Code system. We have letters of the alphabet (which are 26 in total). Bear in mind that being upper case or lower case constitutes a different ASCII Code. Then we have the numbers i.e. 0 to 9. There are also special characters, for example, mathematical symbols – 33 in total. The total of all these different alphanumeric characters is 95.
EBCDIC – Extended Binary Coded Decimal Interchange Code
This is yet another commonly used alphanumeric code system. It is different from the ASCII one in that it is 8 bit. This means it can actually represent a total of 256 alphanumeric characters. It is worth noting that this code system was developed by IBM. Just like ASCII, EBCDIC is also not well suited to handle languages other than English. This effectively makes both ASCII and EBCDIC riddled with issues regarding widespread compatibility – they are found wanting on that front. Before we proceed, let us look at some history.
How It All Began
Morse Code
Alphanumeric codes have evolved over the years. The very first was the Morse Code – introduced by Samuel F.B. Morse in 1837. This type of code is comprised of sequences of varying lengths of elements. These elements follow a standardized system or pattern which makes them represent the different parts of a message. These parts can be alphabetic letters, symbols, and so on.
You are probably wondering how those elements we mentioned earlier are made, right? Well, they can be made through making certain sounds or pulses, for example – they are referred to as dots or dashes. A quick example could be the digit five – it would be represented by five successive dots. Morse code is very limited and is not suited for electronic modes of communication.
Baudot and Hollerith Codes
The former came about around the 1860s whereas the latter came about 36 years later. They were developed by Emile Baudot and Herman Hollerith respectively. The Baudot Code used a system of 5 elements that would represent the alphabet. Applications for this code were mainly telegraphic communications involving the Roman Alphabet.
The Hollerith Code employed the use of punched cards as a means for tabulating. This was essentially a 12-bit code system. The Hollerith Code had a close connection to ASCII codes in that Hollerith strings could be encoded as 2 ASCII characters. However, the Hollerith Code has since become unusable. Anyways, these 3 types of alphanumeric codes (Morse, Baudot and Hollerith) we have briefly looked are just to put things into perspective i.e. how it all began.
Now let us get back to modern alphanumeric code by looking at something universal. We have already seen that the 3 old alphanumeric codes had several limitations. One of those limitations was failure to be effectively used for electronic applications e.g. for Morse Code. We have also looked at ASCII and EBCDIC which do have some great functionality but have certain limitations. The biggest issue is not being universally compatible due to limitations on the language front i.e. only supporting English.
Just by looking at this you can only hope that there would be some universal code that can be there for universal compatibility. Well, there actually is and it is called Unicode – compound word for Universal Code. Let us briefly look at Unicode.
Unicode
Unicode was developed with the thrust of wanting to come up with something universal. Earlier we pointed out that the ASCII Code system is 7 bit whereas the EBCDIC system is 8 bit. You must also know that there are variations in those respective alphanumeric code systems. When it comes to Unicode we are looking at a 16 bit alphanumeric code system. Do you know what that means in terms of total number of characters that can be represented? Well, the total is 65 536 characters – this means that not only all alphanumeric characters are covered but also all languages. It also covers any possible symbols or characters found in technical or science-based fields.
The field of alphanumeric codes is somewhat complex. Some people find the technical details very perplexing because you will be dealing with complex math-based calculations. That is why we endeavoured to just be as simple as possible so that you get a basic picture of what is involved. It all comes from the fact that computers can only understand ones and zeros – that is why alphanumeric codes exist.



